



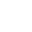



项目安排
对项目任务复杂度进行评估,合理指定分配计划及验收时间。
安置费模块:
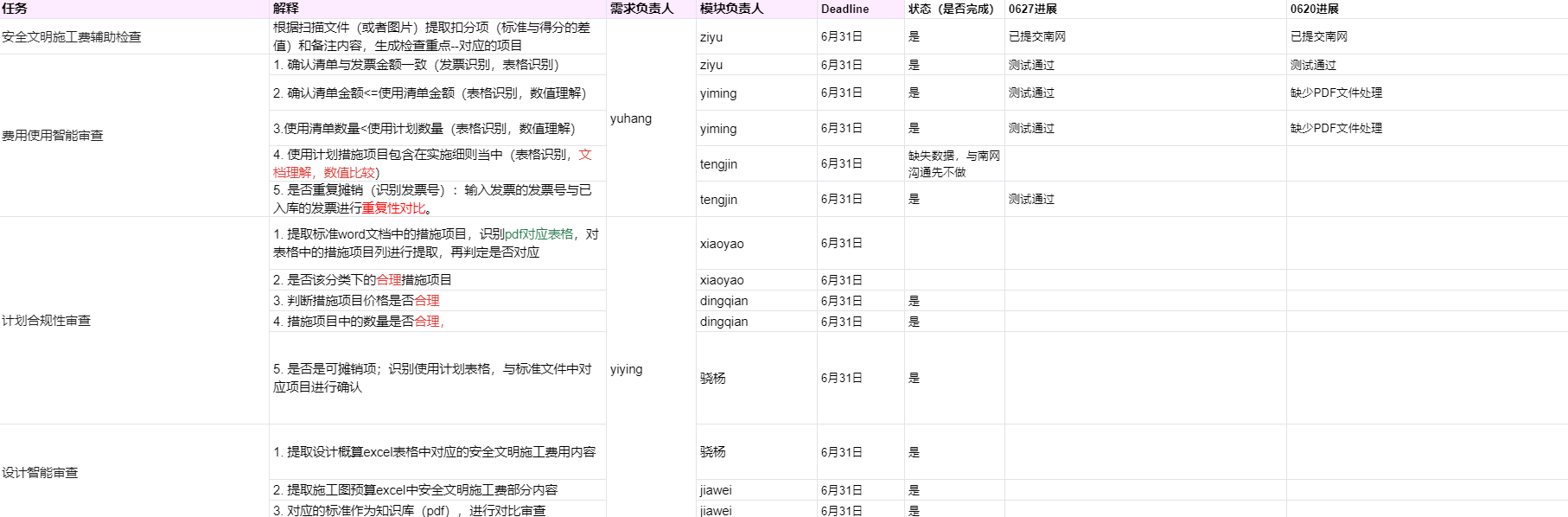
危大项目模块:
任务需求及个人理解
数据说明:
- 云南电网有限责任公司安全文明施工费使用管理标准(试行).docx
- 1 220kV寒武(九村)输变电工程 安全生产投入费使用计划方案报审表及附件.pdf
安置费:
需求1:提取标准Word项目主题,识别扫描文件表格中的项目主题信息,判断是否对应;
需求2:依据标准规范文档,判断扫描文件表格中项目措施在对应项目主题下是否符合要求;
个人理解:
对于任务需求1,主要可分为三大部分,提取管理标准文档中的项目主题、提取扫描文件的项目主题信息、信息进行对比。
- 管理标准项目主题提取:管理文档是Word文档,通过对任务理解,项目主题信息存储在文档的表格中,直接对word文档中的所有表格进行提取,并将其投入到LLM中进行特定信息提取,
Doucment+LLM_prompt. - 申报表项目主题提取:申诉表是一份扫描件pdf文档,内部信息均为图片扫描,信息格式为表格,
Vlm - 信息对比:将上述两份结果提交给LLM,直接进行核对,
LLM_prompt.
对于任务需求2,分为几大部分,提取标准文档中项目主题及其对应的项目措施,提取扫描文件中的项目主题及对应措施、核对是否在对应主题下符合要求。
- 提取标准文档信息:与需求1相同,相关信息均在同一个表中,通过对管理标准的分析,每个措施主题与一个代码对应,提取代码及对应代码下的措施范围描述。
- 提取扫描文件中的信息:将扫描件PDF的每页分割为图片进行识别,将识别结果进行提取,主要分为措施代码及项目措施。
- 核对是否在对应主题下:直接借助LLM进行核对,
LLM_prompt.
Q:为什么前面使用OCR后续使用VLM?
A:主要有两方面原因,项目方面,最开始标准文本没有整理出来,我的任务是以一张较为规则的png图片(非扫描件)进行的,目标是把所有流程跑通,我就直观想到了OCR。后面标准文本整理,是一份扫描件pdf,我发现有些信息OCR很难识别全面,通过试验,VLM可以较好的满足需求,我就在OCR无法很好完成的地方,使用VLM。
注:OCR 更适合标准化、结构清晰的文本提取任务;而 VLM 面向的是需要语义理解、上下文关联和复杂布局的文档理解场景。OCR传统标准识别,VLM添加有理解功能。
技术模块细节-项目需求
主要结构分为server、src、test,其中server文件夹下是对应需求的服务器模块,src文件夹下面是功能模块,test文件夹下面是测试模块,src中主要以一个Class为主体,下面从该Class入手,进行细节介绍。
class MeasureRationalityChecker:
"""
该类实现“3.计划合规性审查”中“措施项目合理性的判定”,主要具备如下功能:
1. 提取标准文档中“电网工程建设安全文明施工费使用指导模板”表格,内含标准“措施项目”及“措施项目主题”。
2. 提取pdf“安全生产投入费用使用计划”中的“措施项目主题”、“措施类别编码”及“措施项目”信息(“费用使用计划”以png格式输入进行识别,内含pdf输入转为png功能)。
3. 判定计划中的措施项目主题是否符合标准文档中的措施项目主题要求标准。
4. 判定计划中的措施项目是否符合标准文档中对应措施项目主题下的要求标准。
"""
初始化class:
def __init__(self):
"""
Initializes the checker.
"""
logger.info("MeasureRationalityChecker initialized")
标准文档信息提取
标准文档表格提取,通过问题分析,项目需要的主要信息均存储在文档的特定表格中,首先对word文档中的所有表格进行提取,之后提交给LLM提取特定的表格:
def identify_specific_tables(
self,
documentation_file_path: str,
) -> str:
logger.info("Extract the Word standard table extraction")
doc = Document(documentation_file_path)
tables = []
for table in doc.tables:
data = []
for row in table.rows:
row_data = [cell.text.strip() for cell in row.cells]
data.append(row_data)
df = pd.DataFrame(data)
tables.append(df)
tables_str = [df.to_string() for df in tables]
prompt = f"""
以下用三个反引号分隔的是从“云南电网有限责任公司安全文明施工费使用管理标准(试行).docx”Word文档中提取的所有表格,\
Word文档提取表格集合:'''{tables_str}'''\
各个表格以DataFrame格式存储在一个列表中,遍历所有所有表格,提取出特定表格“电网工程建设安全文明施工费使用指导模板”,并输出提取出的表格,
该表格的特征如下:
1. 该表格包含['费用类型及取费建议', '措施类别及使用范围', '措施类别编码', '是否可摊销', '变电', '线路', '配网'],7列指标;
2. 其中'费用类型及取费建议'包含['安全生产费', '文明施工费', '环境保护费']三类费用信息;
注意:
- 直接返回表格信息,不要输出实现该功能的python代码;
返回说明:返回特定表格的信息,不要求文字说明。
"""
messages = [
{"role": "user", "content": prompt}
]
response = llm_client.chat(
model=LLM_MODEL,
messages=messages,
stream=False, # 不启用流式输出
)
return response.choices[0].message.content.strip()
注:这里最好可以将表格提取作为静态方法@staticmethod单独提出,作为工具。
对于特定提取出的表格,“措施类别及使用范围信息”列需要单独进行处理,将表格内容投入到新的LLM中,分为项目措施及项目措施范围。
# 提取所有措施类别及使用范围
def extraction_categories_scope(self, documentation_file_path: str) -> json:
prompt = f"""
以下用三个反引号分隔的是一份“电网工程建设安全文明施工费使用指导模板”表格,包含['费用类型及取费建议', '措施类别及使用范围', '措施类别编码', '是否可摊销', '变电', '线路', '配网'],7列指标;
“电网工程建设安全文明施工费使用指导模板”表格:{self.identify_specific_tables(documentation_file_path)}
提取出“措施类别及使用范围”列信息,将该信息拆分为“措施类别”及“使用范围”,输出格式用json,下面大括号的是示例:
{{
“措施类别及使用范围信息”:[
“安全文明施工相关制度体系建立(整理编制费用)”,
“施工现场管理设施(进出现场设施物品、视频监控器材等购置、租赁、安装、运行、检修费用)”
]
拆分为“措施类别”及“使用范围”,返回:
{{
“安全文明施工相关制度体系建立”: “整理编制费用”,
“施工现场管理设施”: “进出现场设施物品、视频监控器材等购置、租赁、安装、运行、检修费用”
}}
}}
"""
messages = [
{"role": "user", "content": prompt}
]
response = llm_client.chat(
model=LLM_MODEL,
messages=messages,
stream=False, # 不启用流式输出
)
result = response.choices[0].message.content.strip()
# logger.info(f"Extract all themes of measures and their scope of application\n{result}")
logger.info(f"Extract all themes of measures and their scope of application")
return result
申报表信息提取
申报表为扫描件pdf,需要提取扫描件中表格内的信息,主要运用如下两种方法,OCR与VLM。



